Совместное применение парадигм HPC, HTC, CLOUD
и эластичные приложения.
и эластичные приложения.
Русский термин "высокопроизводительные вычисления" охватывает сразу два аналогичных англоязычных термина: High Performance Computing и High Throughput Computing. Первый термин относится к области задач высокой вычислительной сложности, таких как предсказание погоды или моделирование ядерных реакций и охватывает аппаратные и программные средства, с помощью которых решаются эти задачи: кластеры с высокоскоростными интерфейсами связи между многочисленными процессорами и средства построения распределенных приложений, такие как библиотеки MPI (Message Passing Interface), PVM (Parallel Virtual Machines) или OpenMP.

Второй термин - HTC, имеет также синоним Grid Computing и относится к области массовых вычислений, нацеленных на решение большого количества относительно простых независимых задач, для решения которых не требуется межпроцессного обмена на большом количестве обычных (т.е. не оснащенных высокопроизводительными средствами межпроцессной коммуникации) компьютеров. Хорошим примером задач НТС является перебор паролей. Программные средства, относящиеся к этой категории - разнообразные планировщики типа LSF, SGE, Univa итд. В парадигме HTC пользовательское приложение не требует использования никаких специальных библиотек и особых подходов к программированию.
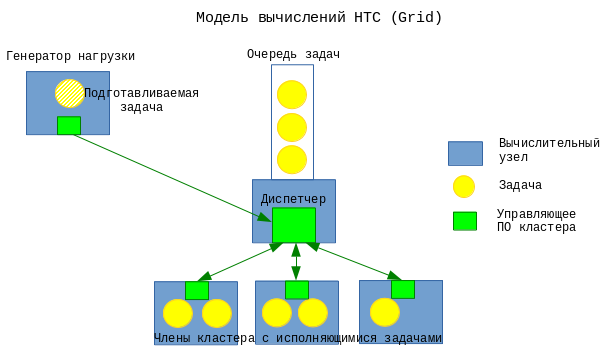
Планировщики задач HTC также применяются в сфере HPC для запуска необходимого количества исполняемых модулей распределенного приложения на многих узлах суперкомпьютера. На рис. 3 показан пример кластера, на котором уже исполняются распределенные приложения “А” и “Б”, а приложение “В” находится в процессе запуска.
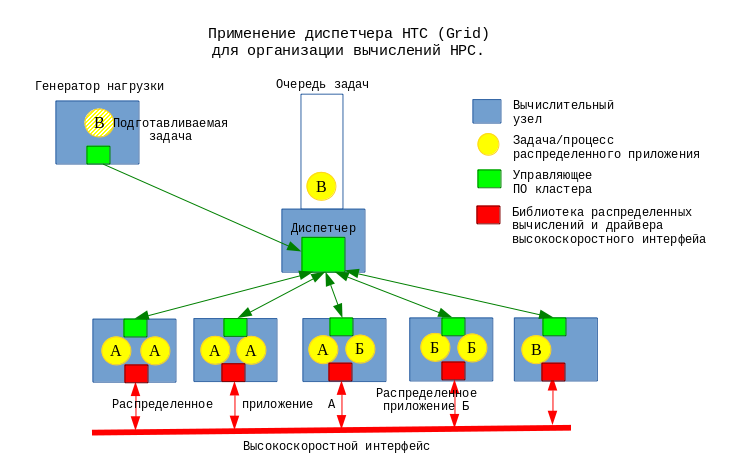
Сверхпопулярная сегодня концепция облачных вычислений на первый взгляд к высокопроизводительным вычислениям отношения не имеет, здесь речь идет о крупных вычислительных мощностях, распределяемых между множеством независимых заказчиков, запускающих, как правило, бизнес-приложения, хостинг web и БД.

Однако, облачные системы также могут являться поставщиком "большого количества ядер" для нужд суперкомпьютерных вычислений. Конечно, латентность передачи сообщений между отдельными процессами в облаке выше, чем в традиционном суперкомпьютере, что отрицательно сказывается на производительности распределенного приложения, но существует достаточно большое количество задач, которые не слишком требовательны к скорости межпроцессного взаимодействия и для которых такое ухудшение инфраструктуры не критично. Помимо этого некоторые реализации облачных сервисов используют для связи между хранилищами данных и гипервизорами те же самые высокопроизводительные интерфейсы, которые ранее применялись исключительно в области HPC, что делает потенциально возможным применение этих платформ облачных вычислений в режиме полноценного HPC.

В то время как совместное применение средств HPC+Cloud и HPC+HTC носит чисто технологический характер, обеспечение взаимодействия между контроллером облака и планировщиком задач HTC открывает принципиально новые возможности управления вычислительным процессом:
облако само по себе позволяет выделить абоненту столько оборудования, сколько позволяют финансы. При этом текущий уровень нагрузки (например, количество параллельно исполняемых задач или длина очереди задач) в системе абонента не учитывается, то есть с точки зрения уровня нагрузки выделение реурсов статично.
HTC-планировщик сам по себе динамически подгоняет профиль нагрузки к возможностям конкретного аппаратного окружения, не влияя на характеристики этого окружения.
Интеграция этих сервисов позволяет выделять вычислительные мощности облака абоненту не статически, а с учетом текущего профиля нагрузки, генерируемой абонентом. Для реализации такой системы диспетчер пакетных вычислений должен уметь подавать контроллеру облака (имеется в виду облако IaaS) команду на развертывание дополнительной виртуальной машины, сконфигурированной, как член кластера и динамически вводить эту машину в кластер, а также проводить обратную операцию - исключать лишнюю машину из кластера и подавать контроллеру облака команду на нее отключение.
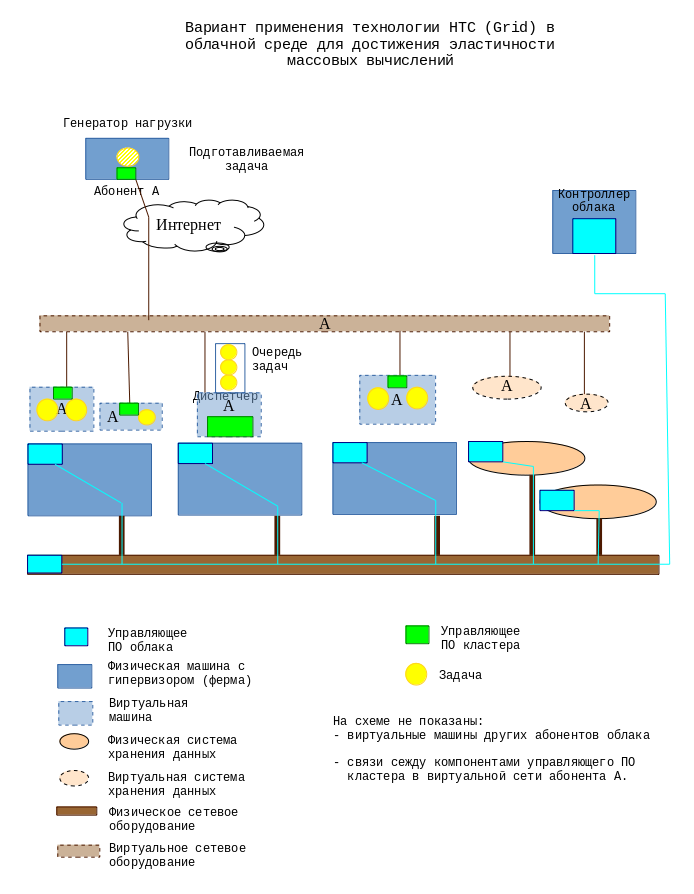
Таким образом вычислительные ресурсы мобилизуются только на то время, пока они действительно необходимы. Это свойство вычислительной системы называется эластичностью. Применение эластичной среды обработки при фиксированной цене за вычислительные ресурсы и виртуально неограниченных мощностях облачных ЦОД, позволяет максимально сократить время расчетов. При этом оплата становится пропорциональной объему проведенных вычислений. В настоящее время свойством эластичности обладают в основном web-приложения, в которых балансировщик нагрузки является абсолютно отдельным компонентом и разрабатывается независимо от собственно приложения (бизнес-логики).
Приложения общего назначения и HPC-приложения, построенные по современной архитектуре, свойством эластичности не обладают и не в состоянии воспользоваться эластичностью среды исполнения. Наиболее известная библиотека для построения распределенных вычислений MPI предполагает, что количество ядер, выделенных задаче, неизменно от момента ее запуска до завершения и вынуждает разработчика планировать архитектуру программы, особенно логику обмена сообщениями между отдельными ее процессами, исходя из этого предположения. Такой подход является наилучшим для достижения максимальной производительности на сложных задачах, характеризующихся высокой связностью, т.е. требующих интенсивного обмена информацией между отдельными процессами и способных получить значительный выигрыш в производительности при условии оптимизации схемы межпроцессных взаимодействий с учетом тонкостей аппаратной реализации (топологии) сети связи конкретного суперкомпьютера.
В случае формирования "суперкомпьютера" из ресурсов облака, как это описывается в статьях http://buildacloud.org/blog/181-high-performance-computing-and-cloudstack.html и http://cyclecomputing.com/blog/cyclecloud-50000-core-utility-supercomputing/, необходимо сначала полностью развернуть инфраструктуру, т.е. создать и запустить все необходимые виртуальные машины, и только потом запускать HPC-приложение. Аналогично, остановка виртуальных машин и освобождение их ресурсов может проводиться только после полного завершения работы приложения, даже если значительная часть процессоров простаивает.
Однако по крайней мере для некоторых типов задач, не требующих сложных алгоритмов передачи сообщений, возможно предложить другой подход к построению распределенного приложения, позволяющий использовать свойство эластичности вычислительной системы для достижения эластичности самого приложения. Архитектура такого приложения уподобляется архитектуре HTC-кластера: распределенное приложение включает в себя один или несколько генераторов нагрузки, диспетчер команд, управляющий очередью, и несколько исполнителей. Генераторы нагрузки осуществляют следующие задачи:
взаимодействие с пользователем,
разбиение полученной задачи на фрагменты,
описание фрагментов задачи и отправка команд на их обработку диспетчеру,
сбор результатов обработанных задач,
визуализация полученных результатов.
Диспетчер поддерживает связь с генераторами нагрузки и исполнителями и распределяет команды на обработку данных между исполнителями с учетом их загруженности, имеющихся ресурсов и других факторов.
Исполнитель получает команды на обработку данных от диспетчера и выполняет их, возвращая результат генератору нагрузки напрямую, или через диспетчер, или путем изменения внешних хранилищ информации (файлы, СУБД).
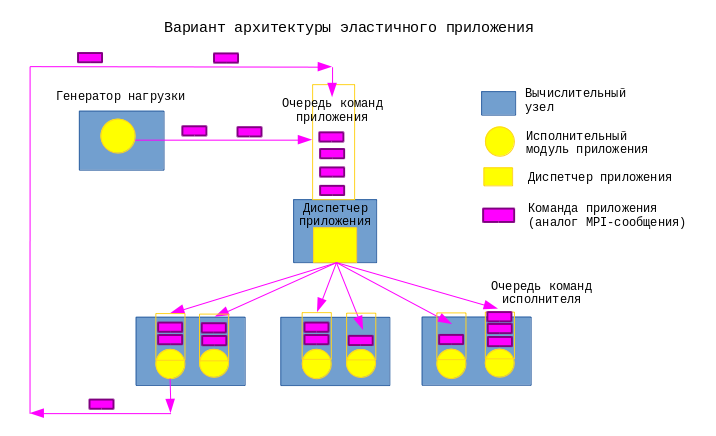
Исполнители могут быть как однотипными, так и специализированными, т. е. имеющими различные наборы команд. Один и тот же процесс может быть одновременно и генератором нагрузки и исполнителем.
В простейшем случае все компоненты приложения (генератор нагрузки, исполнитель и диспетчер) могут являться одним и тем же исполняемым файлом, запускаемым в разных режимах. Код такой программы будет содержать все возможные ветви исполнения, т. е. варианты исполнения всех команд во всех ролях, подобно тому, как это принято в программах стандартов MPI и OpenMP. Такая реализация позволяет диспетчеру самостоятельно обрабатывать команды в случае отсутствия выделенных исполнителей (например в режиме отладки).
Возможен и противоположный сценарий — распределенное приложение строится из специализированных исполняемых модулей(возможно созданных разными разработчиками), реализующих различные наборы команд, соответствующие различному функционалу, например различным автоматизированным рабочим местам в составе АСУ. Модули объединяются в единую информационную систему с помощью унифицированного диспетчера из функциональности которого исключены все задачи, кроме собственно диспетчеризации команд между исполнителями и генераторами нагрузки.
Суммарная вычислительная мощность, доступная такому распределенному приложению, определяется количеством запущенных экземпляров модулей-исполнителей и мощностью процессоров вычислительных узлов, на которых работают исполнители.
Для обеспечения свойства эластичности приложения диспетчер приложения должен иметь возможность подстраивать объем доступных приложению вычислительных мощностей путем взаимодействия с эластичной средой исполнения, т. е. диспетчером HTC (Grid) и/или контроллером облака.
Ситуация нехватки вычислительных мощностей, выделенных распределенному приложению может определяться по следующим признакам:
длина очереди команд диспетчера превышает порог,
длина очереди команд диспетчера растет,
среднее время ожидания в очереди команд диспетчера превышает порог,
среднее время ожидания в очереди команд диспетчера растет.
В такой ситуации диспетчер приложения отправляет диспетчеру HTC (Grid) запрос на запуск еще одного модуля-исполнителя. Вновь запущенный исполнитель устанавливает связь с диспетчером приложения, сообщает ему список команд, которые он способен выполнять и текущую загрузку своего процессора, после чего диспетчер приложения начинает отправлять ему команды из своей очереди.

Возможен случай, когда диспетчер HTC (Grid) обнаружит, что на выделенных ему в облаке ресурсах (вычислительных ядрах, памяти) эффективно запустить еще один процесс невозможно. Например, распределенное приложение выполняют 40 исполнителей, запущенных в 10 виртуальных машинах, имеющих по 4 ядра каждая, при этом каждый исполнитель использует 100% процессорного времени своего ядра. В такой ситуации запуск дополнительного исполнителя в одной из виртуальных машин приведет к распределению той же самой вычислительной мощности 4 ядер между пятью исполнителями вместо четырех и лишь увеличит накладные расходы на функционирование одного исполнителя. Чтобы реально увеличить доступную вычислительную мощность в данной ситуации, диспетчер HTC (Grid) должен отправить запрос контроллеру облака, который может отреагировать на него следующими способами:
добавить вычислительное ядра в одну из виртуальных машин, отведенных под распределенное приложение, после чего диспетчер HTC сможет запустить на ней еще один экземпляр исполнителя без негативных эффектов,
создать новую виртуальную машину, сконфигурировать ее в качестве члена HTC-кластера, после чего диспетчер HTC сможет запустить еще один экземпляр исполнителя на новой виртуальной машине.
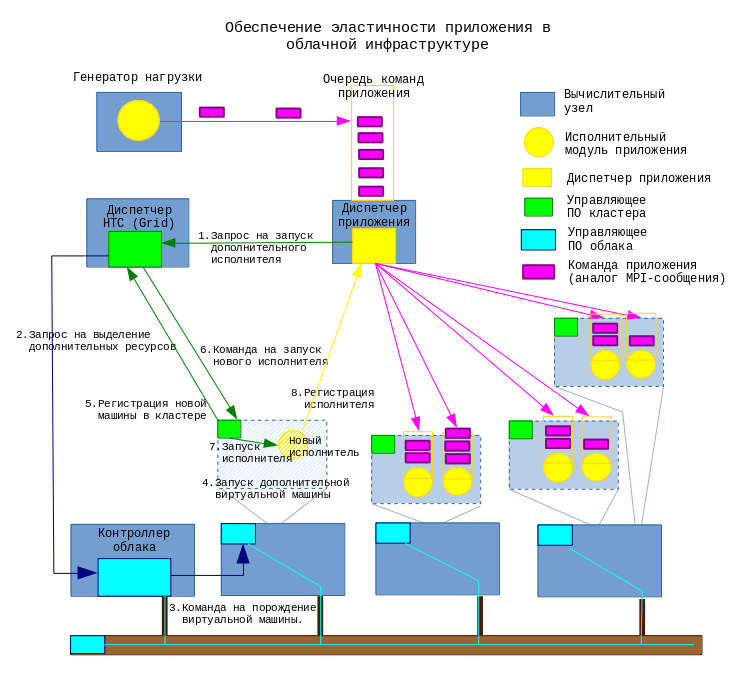
Процедура отказа от излишней вычислительной мощности более сложна — обнаружив, что отведенные ресурсы избыточны, диспетчер приложения не может мгновенно отключить какой-либо исполнитель. Сначала необходимо дождаться, пока тот завершит обработку команд, имеющихся в его локальной очереди. Кроме того — завершение процесса-исполнителя позволяет выделить освободившуюся вычислительную мощность другому приложению в рамках HTC-кластера, либо уменьшить количество выделенных ядер, но не гарантирует возможности останова виртуальной машины и возврата ее ресурсов в облако, что наиболее ценно с экономической точки зрения. Для обеспечения такой возможности диспетчер приложения должен обладать информацией о размещении своих исполнителей по машинам и иметь определенную стратегию освобождения ресурсов, например «сначала освобождать самые крупные виртуальные машины» или «сначала освобождать наименее занятые».
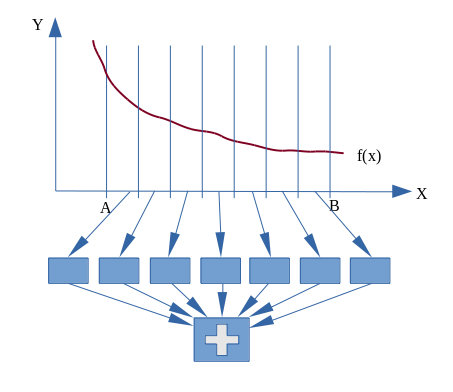
Для эффективного функционирования такой комбинированной инфраструктуры предстоит решить ряд технических задач, связанных с оптимизацией распределения исполнителей по вычислительным ресурсам и оптимизацией реагирования системы на несоответствие отведенных вычислительных мощностей имеющемуся объему задач в условиях динамического изменения этого объема. Но самое главное — разработка распределенных эластичных приложений, алгоритм которых существенно отличается как от обычных непараллельных программ, так и от распространенных стандартов параллельного программирования. Чтобы проиллюстрировать различия в подходе к распараллеливанию алгоритма, рассмотрим одну из простейших задач - вычисление определенного интеграла методом прямоугольников или трапеций. С точки зрения распараллеливания нас для нас наиболее важно следующее свойство интеграла:

Это свойство дает нам право разбить интервал интегрирования на несколько отрезков, параллельно вычислить интегралы на каждом из них и затем сложить полученные значения.
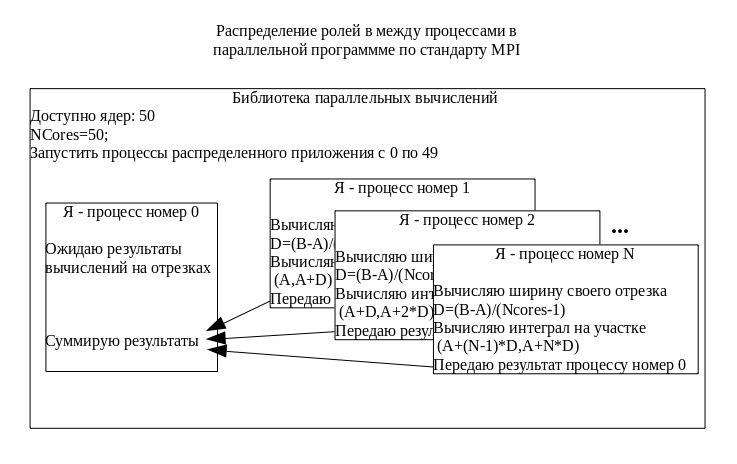
В параллельных программах, разработанных по стандарту MPI, количество подзадач, на которые разбивается исходная задача (в данном случае это количество отрезков, на которые будет разбит интервал интегрирования) определяется количеством выделяемых процессоров, которое задается при запуске приложения командой вида mpirun -np <N> integral.
В предлагаемой архитектуре количество исполнителей заранее неизвестно и может варьироваться в ходе исполнения, поэтому разбиение задачи на подзадачи должно основываться на каких-то других критериях. В случае с задачей интегрирования это может быть например количество накладных расходов по порождению подзадачи или ориентировочное время выполнения подзадачи.
